# Master Gradient Descent and Binary Classification: Supervised Machine Learning – Day 9
Table of Contents
A break due to sick
Oh boy… I was sick for almost two weeks 🤒 After a brief break, I’m back to dive deep into machine learning, and today, we’ll revisit one of the core concepts in training models—gradient descent. This optimization technique is essential for minimizing the cost function and finding the optimal parameters for our machine learning models. Whether you’re working with linear regression or more complex algorithms, understanding how gradient descent guides the learning process is key to achieving accurate predictions and efficient model training.
Let’s dive back into the data-drenched depths where we left off, shall we? 🚀
The first coding assessment
I couldn’t recall all of the stuff actually. It’s for testing implementation of gradient dscent for one variable linear regression.
I did a walk through previous lessons and I found this summary is really helpful:

This exercise enhanced what I’ve learnt about “gradient descent” in this week.
Getting into Classification
I started the learning of the 3rd week. Looks like it will be more interesting.
I made a few notes:
-
binary classification
-
negative class not mean “bad”, but absense.
-
positive class not mean “good”, but presence.
-
New english words: benign, malignant
-
logistic regression - Even though, it has “regression” in the name, but it’s for classification.
-
threshold
-
sigmoid function or logistic function
-
-
decision boundary
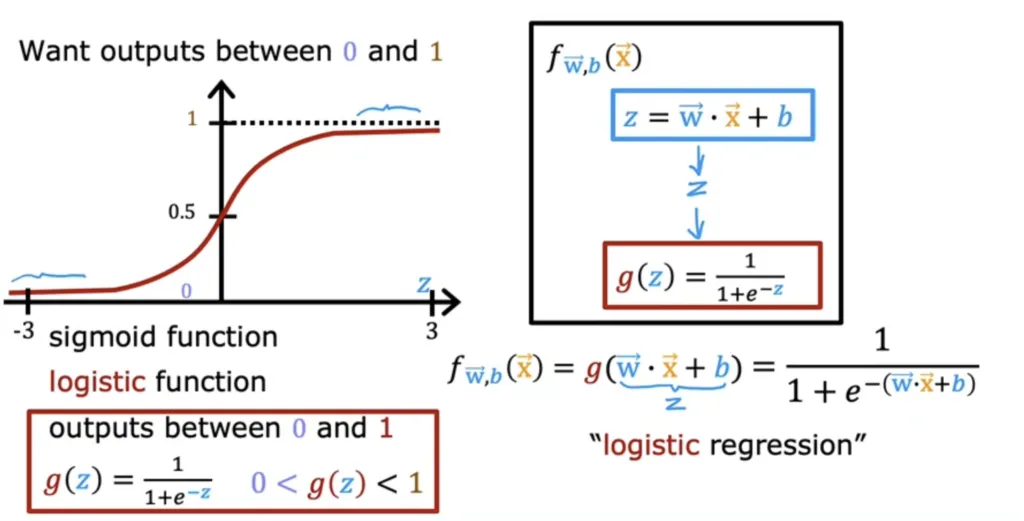
Probability that y is 1;
Given input arrow x, parameters arrow w, b.
I couldn’t focus too long on this. Need to pause after watching a few videos.
Bye now.
Ps. feel free to check out my other posts in Supervised Machine Learning Journey.